
Uniform Distribution#
The Uniform Distribution is used when all events in a given sample space are equally likely to occur. We see this distribution in tossing a fair coin, rolling a die, or using a random number generator. Notice these examples include both discrete and continuous random variables. The Uniform Distribution has both discrete and continuous versions! First we will discuss the discrete version.
Discrete Uniform Empirical Distribution#
As a simple example, we’ll build an empirical distribution of rolls of a six-sided die.
So far we have randomly sampled from a list or array. We can also randomly sample from DataFrames! This is advantageous in the situation where we want to select a random subset of data to build predictive models or to analyze.
First, we create a six-sided die DataFrame.
die = pd.DataFrame(
{
'Face': np.arange(1, 7),
}
)
die
| Face | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
We see that this DataFrame has 6 rows and 1 column.
Similar to randomly selecting an option from a list, we can randomly sample from a DataFrame, using the DataFrame’s sample method.
This method randomly selects an entire row or rows from the DataFrame. Below, the input argument 1 denotes that we want to select exactly one row. We can choose to sample more than one row by changing this input.
die.sample(1)
| Face | |
|---|---|
| 0 | 1 |
Some additional arguments to this function include:
replace: whether to “replace” rows for re-sampling (note:np.random.choice()also has this argument!)random_state: the initial state of the pseudo-random generator
Setting the replace option to True allows us to sample the same row more than once. With this option, we are choosing a row, replacing it in the “pool” of options to sample, and choosing our next row from the original DataFrame. Setting this option to False allows us to choose a row at most once. The default in pandas is replace=False.
Setting the “random state” equal to some integer allows for reproducibility of results. With this option, sample still gives as “random” a result, but it will be the same “random” result each time we run our experiment. (“True” randomness is, after all, the domain of quantum mechanics!) Note that for now this is not extremely important, but it will be useful for predictive modeling in the future.
die.sample(10, replace=True, random_state=1)
| Face | |
|---|---|
| 5 | 6 |
| 3 | 4 |
| 4 | 5 |
| 0 | 1 |
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
| 0 | 1 |
| 0 | 1 |
| 1 | 2 |
Above, we randomly sampled 10 numbers between one and six (inclusive) with replacement corresponding to our rolling a die 10 times. This is an example of a probabilistic sample as the chance of each face landing upright is 1/6, and we know this before rolling the die.
We can now visualize the results of these random samples with a barchart. This will give us an idea of the how often each number is rolled.
If we only roll the die 12 times, some numbers appear with much greater frequency than others. (Notice that 3 doesn’t appear at all in the graph below since it appeared 0 times in the sample)
# This code takes a sample of 12 die, looks at the faces column of the dataframe,
# counts the number of times each value occurs, sorts them from 1 to 6, the plots a bar chart
#
# Note we use a barchart to depict a discrete distribution
die.sample(12, replace=True, random_state=1).Face.value_counts().sort_index().plot.bar();
plt.xlabel('Face');
plt.ylabel("Number of Occurrences");
plt.title("Distribution of Dice Rolls");
plt.show()
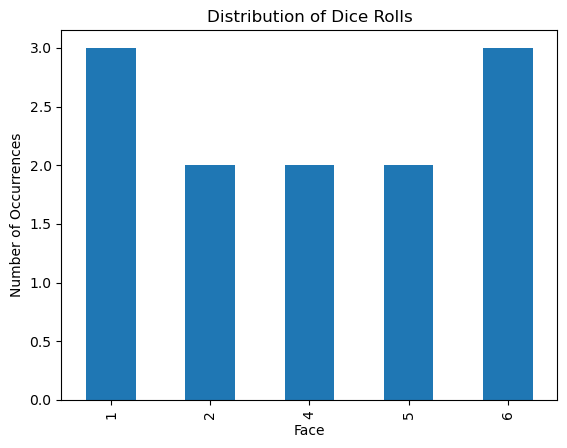
Randomly sampling 1,000 rolls of the die we start to see a more evenly distributed graph.
die.sample(100, replace=True).Face.value_counts().sort_index().plot.bar();
plt.xlabel('Face');
plt.ylabel("Number of Occurrences");
plt.title("Distribution of Dice Rolls");
plt.show()
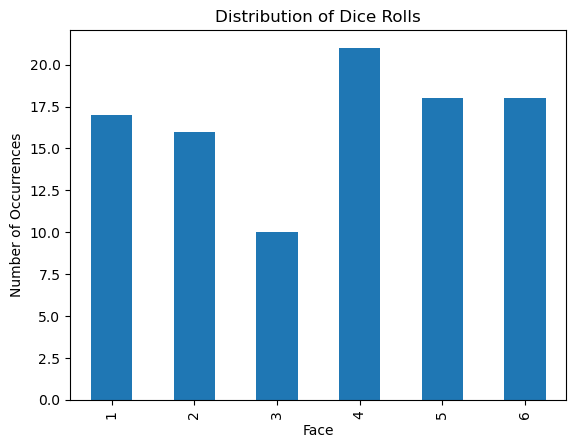
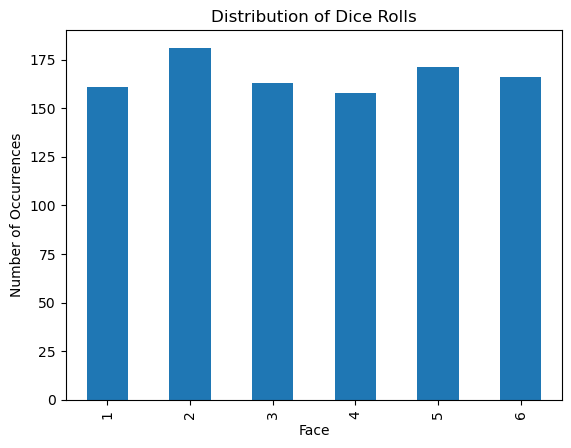
Let’s see how the distribution changes as we increase the number of randomly sampled rolls of a six-sided die.
die.sample(1_000, replace=True).Face.value_counts().sort_index().plot.bar();
plt.xlabel('Face');
plt.ylabel("Number of Occurrences");
plt.title("Distribution of Dice Rolls");
plt.show()
die.sample(10_000, replace=True).Face.value_counts().sort_index().plot.bar();
plt.xlabel('Face');
plt.ylabel("Number of Occurrences");
plt.title("Distribution of Dice Rolls");
plt.show()
die.sample(100_000, replace=True).Face.value_counts().sort_index().plot.bar();
plt.xlabel('Face');
plt.ylabel("Number of Occurrences");
plt.title("Distribution of Dice Rolls");
plt.show()
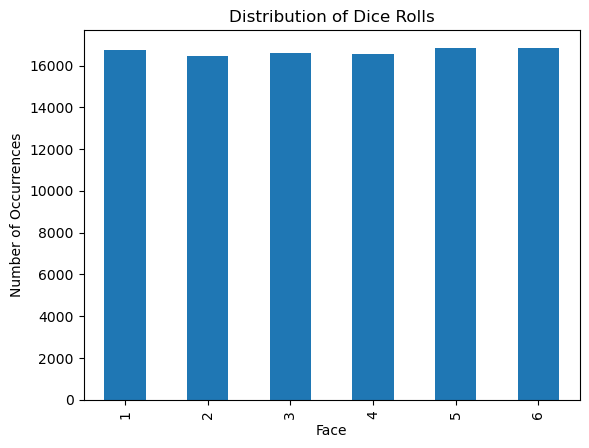
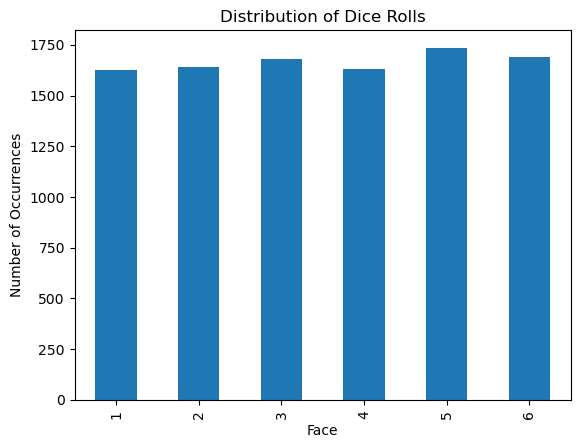
As the number of samples increases – that is, as we roll the die many many many times – we find that the empirical distribution (our observed distribution of dice rolls) shows each face of the die appears roughly the same number of times. As we know the probability of sampling each face of the die is the same, we are seeing our empirical distribution get closer to the true probability distribution of the die, looking more uniform.
This phenomenon is related to a mathematical theorem known as the Law of Large Numbers. The Law of Large Numbers states that, as the number of experiments increases, the mean of the empirical distribution gets closer to the mean of the probability distribution (also known as the expected value).
Let’s look at the mean of the empirical distribution for different numbers of experiments.
np.mean(die.sample(100, replace=True))
np.float64(3.69)
np.mean(die.sample(1_000, replace=True))
np.float64(3.462)
np.mean(die.sample(1_000_000, replace=True))
np.float64(3.500001)
These seem to be approaching 3.5, but in order to know for sure, we need to know more about the probability distribution for our dice rolling example: the Discrete Uniform Distribution.
Discrete Uniform Probability Distribution#
How do we define this rolling of a six-sided die mathematically? We saw above that repeating this experiment yielded a collection of samples from the population for samples of sizes 1,000, 100,000, and larger.
In the case where each outcome is equally likely to occur, the function that assigns probabilities is the uniform distribution. For a sample space containing \(n\) elements, the pmf is defined by:
\(P(X=x)=\frac{1}{n}\) for all x in the sample space S (0 otherwise).
Further, if \(E\) is an event containing multiple elements from the sample space, then:
\(P(E)=\frac{\text{Number of elements in E}}{n}\).
For our example of rolling a six-sided die, each roll has a probability of exactly \(\frac{1}{6} \approx 0.1666\) of occurring. If we take the example of rolling a six-sided die 1000 times and computing the probabilities of each result, we find that, in practice, the empirical probability we rolled a 1 was \(0.171\), not the \(0.1666\) given by the theoretical probability.
#both the np.random.choice and DataFrame.sample functions sample from a uniform distribution by default
empirical_probabilities = (die.sample(1_000, replace=True,random_state=1).value_counts())/1_000
empirical_probabilities
Face
1 0.171
6 0.170
3 0.169
2 0.166
5 0.164
4 0.160
Name: count, dtype: float64
Returning to our discussion of the Law of Large Numbers, what is the expected value (mean) of the Uniform Probability Distribution? The mean of a uniform distribution with pmf \(P(X=x)=\frac{1}{n}\) and sample space S = {1, 2, …, n} is:
\(\mu(X)=\frac{n+1}{2}\).
This corresponds to the average of the elements in our sample space: \(\frac{1+2+...+n}{n}= \frac{\frac{n(n+1)}{2}}{n}= \frac{n+1}{2}\).
In our dice rolling example, n is 6 so the mean of our probability distribution is \(\frac{6+1}{2} = 3.5\). So the means of our empirical distributions are indeed approaching 3.5 as the samples get larger. We can also calculate the variance and standard deviation for the probability distribution of dice rolling. The variance of a uniform probability distribution with sample space sample space S = {1, 2, …, n} is:
\(\sigma^2(X)=\frac{n^2 - 1}{12}\)
which for our example is \(\frac{6^2 - 1}{12} = 2.92\). As the standard deviation is the square root of the variance, the standard deviation of our dice rolling example is 1.71. Let’s check this against our empirical distribution.
np.std(die.sample(1_000_000, replace=True))
Face 1.708526
dtype: float64
What we see in our empirical distribution matches what we would expect mathematically knowing the probability distribution it is approximating. In fact, the Law of Large Numbers says that when \(n\), or the number of samples, is large, the mean and standard deviation from our empirical distribution serves as a good estimate for the mean and standard deviation of the probability distribution.
Continuous Uniform Probability Distribution#
Imagine that instead of sampling from a discrete sample space, as in our dice rolling example, we sample with replacement from a continuous sample space also between 1 and 6. Now, our random variable can take on any real number in this interval. When no outcome has a higher chance than another of being selected (imagine throwing a dart at a number line), this random variable is continuous uniform. We denote a continuous uniform random variable, \(X\), on the interval \([a, b]\) with \(X \sim U(a,b)\). Therefore, a random variable that takes values between 1 and 6 would be denoted by \(X \sim U(1,6)\). The pdf for a continuous uniform random variable is:
\(f(x) = \frac{1}{b-a}\) when \(x\) is between \(a\) and \(b\) and 0 otherwise.
From this distribution, we have:
\(\mu = \frac{b+a}{2}\) (i.e. the middle of the interval) and
\(\sigma^2 = \frac{(b-a)^2}{12}.\)
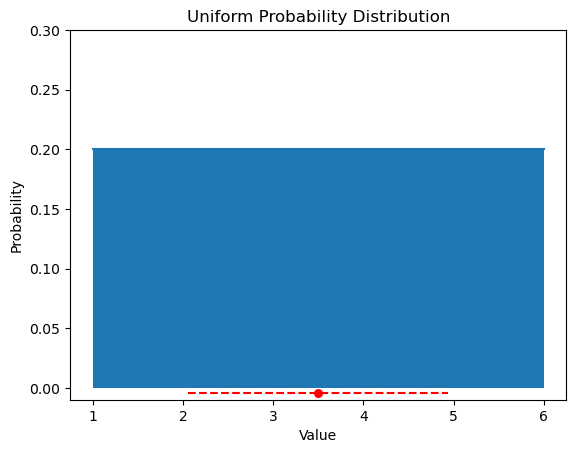
Our continuous random variable \(X \sim U(1,6)\) would have pdf \(P(X=x) = \frac{1}{6-1} = \frac{1}{5}\) when \(x\) is between \(1\) and \(6\) and 0 otherwise. It also has \(\mu = \frac{6+1}{2} = \frac{7}{2}\) and \(\sigma = \sqrt{\sigma^2} = \sqrt{\frac{(6-1)^2}{12}}= \sqrt{\frac{25}{12}} \approx 1.44\)
The graph of this distribution is shown below along with the mean as a red dot and one standard deviation plotted with dashes on either side of the mean.
plt.plot([1,2,3,4,5,6], [0.2]*6)
plt.fill_between([1,2,3,4,5,6], [0.2]*6, 0)
plt.scatter(7/2, -0.004, color='red', s=30)
plt.hlines(y=-0.004, xmin=7/2 - 1.44, xmax=7/2 + 1.44, color = 'red', linestyles = 'dashed')
plt.ylim([-0.01,0.3]);
plt.xlabel("Value");
plt.ylabel("Probability");
plt.title("Uniform Probability Distribution");
Often, it is useful to be able to draw samples from a known distribution like the uniform. Previously, we have used np.random.sample to draw samples from a given list. The np.random module has other useful functions for drawing random samples, including np.random.uniform. This function takes in a value for low and high has well as a size (the number of samples to draw) and draws from the continuous uniform probability distribution on the interval [low to high). Below, we draw 10 random samples from the uniform distribution depicted above.
np.random.uniform(low = 1, high = 6, size = 10)
array([2.99652922, 2.49895357, 2.40252562, 1.48973975, 1.82163087,
2.38431197, 3.58479014, 3.01919991, 4.72114652, 3.05913975])
We can use this random number generator to create an empirical distribution for the continuous uniform.
# Note we use a histogram to depict a continuous distribution
plt.hist(np.random.uniform(1,6,100));
plt.xlabel("Value");
plt.ylabel("Probability");
plt.title("Uniform Empirical Distribution");
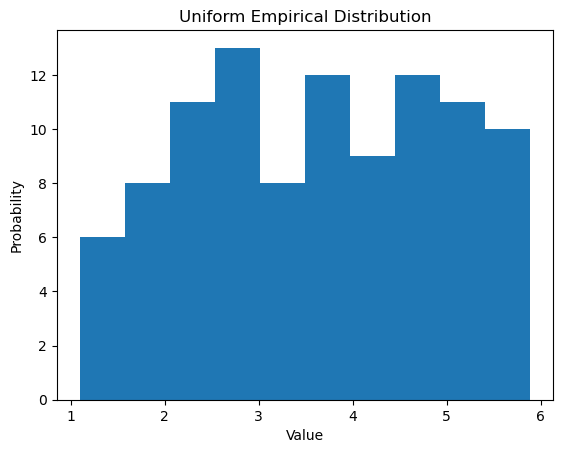
Again, due to the Law of Large Numbers, as the size of the sample increases, we see the histograms look more like the graph of the uniform probability distribution.
plt.hist(np.random.uniform(1,6,1_000));
plt.xlabel("Value");
plt.ylabel("Probability");
plt.title("Uniform Empirical Distribution");
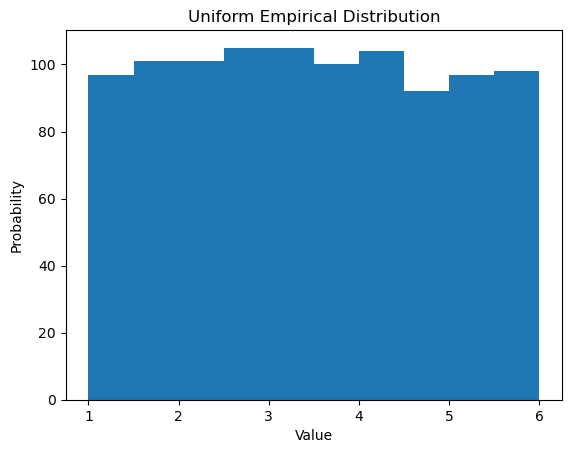
plt.hist(np.random.uniform(1,6,10_000));
plt.xlabel("Value");
plt.ylabel("Probability");
plt.title("Uniform Empirical Distribution");
plt.hist(np.random.uniform(1,6,100_000));
plt.xlabel("Value");
plt.ylabel("Probability");
plt.title("Uniform Empirical Distribution");
The mean and standard deviation approach the theoretical values we calculated as well.
np.random.uniform(1,6,100_000).mean()
np.float64(3.498592463951222)
np.random.uniform(1,6,100_000).std()
np.float64(1.4437310848492866)
Next we will discuss one of the most commonly used probability distributions of all: the Normal Distribution.