
Sampling#
In both experimental and observational studies, the goal is to come to a conclusion about a certain population. That population may consist of cancer patients, residents of Hyde Park, or people reading this data science book. A survey of every unit – or individual member – of a population is known as a census. Often, it is not possible to collect data on every subject in a population. For example, I may be able to survey all students taking my course, but it would be difficult to survey every Hyde Park resident. This is due to logistical issues, the amount of time it would take, and the expense. For these reasons, researchers often study a sample of the population and use that sample to gain information about the entire population through statistical inference. Numerical characteristics of the sample are known as statistics. Statistics are used to estimate or infer values of parameters, which are numerical characteristics of the entire population.
Sampling Designs#
In order to be able to generalize from the sample to the population as a whole, the sample must be representative of the population. Otherwise, inference on that sample may produce misleading conclusions. For example, if a researcher is interested in understanding how those living on the southside of Chicago view the University of Chicago, and the researcher collects a sample of 50 first years attending the University of Chicago, the feelings of this sample of first years is most likely not representative of the feelings of everyone living on the southside. Similarly, if a cancer researcher wants to know how well a drug works on cancer patients, but uses a sample consisting only of men under 30, any conclusions she might draw from the experiment cannot be generalized to the entire population but rather only to the population of men under 30. When a sample is not representative of the population it is considered biased.
Simple Random Sampling#
There are several sampling designs (AKA sampling schemes), or processes by which a sample is collected, that are meant to help collect representative samples. The first is a simple random sample (SRS). In a simple random sample of size n, every group of n units in the population has an equal chance of being selected as the sample. This ensures that portions of the population are not over- or under-sampled. The figure below shows a simple random sample of 10 units (shown in maroon) taken from a population of 100.
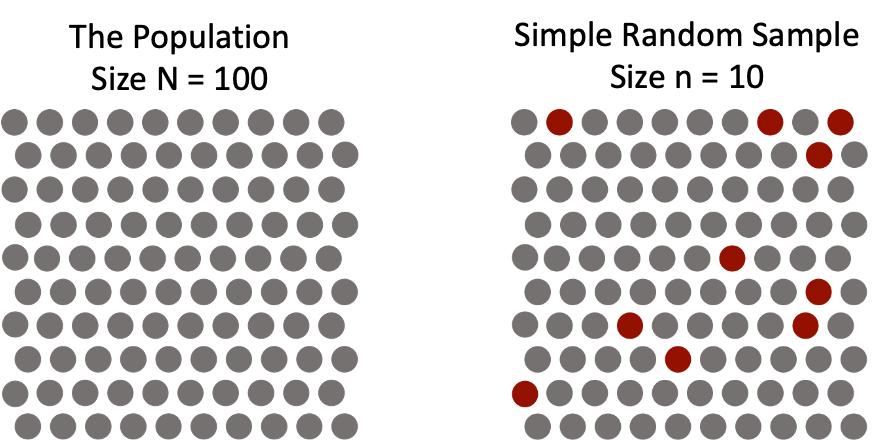
For example, suppose I have five colored marbles in a hat and I draw one marble from the hat without looking. All marbles have the same chance of being selected, one in five. Therefore, my marble choosing example is a SRS. We can conduct a SRS easily in Python using the np.random.choice function introduced in Chapter 5. The following code uses np.random.choice to randomly select a color from the array marbles [1]. By default, it will conduct a SRS, meaning that all elements in marbles have an equal chance of being chosen.
import numpy as np
np.random.seed(1890)
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles)
'brown'
The function np.random.seed() takes in an integer and uses it to set the state of the random number generator. For now, you don’t need to understand how this works, only that it makes the results of our random.choice the same for anyone using the same integer as their seed. Repeating with the same random seed produces the same result: ‘brown’.
np.random.seed(1890)
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles)
'brown'
Let’s try a new seed.
np.random.seed(123)
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles)
'yellow'
By changing our seed, we got a different result. Throughout this book, we will set random seeds so that, by setting the same seed on your computer, you can replicate the examples done here.
Now, suppose I take the yellow, green, and brown marbles out of my hat. Now these marbles have no chance of being chosen and the red and blue marbles each have a 1 in 2 chance of being chosen. We can depict this in code by creating a new marbles list and taking a SRS.
marbles = ["red", "blue"]
np.random.choice(marbles)
'red'
Or, we can give different elements different chances of being chosen by using the argument p which takes in a list of the same size as marbles. Each element in the p list corresponds to an element of marbles, and together they must add to 1 (the reasoning for this will be explained further in the next chapter). The last 3 elements are 0 since those marbles have no chance of being chosen. The first two are 0.5 or \(\frac{1}{2}\) since they have a 1 in 2 chance of being chosen.
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles, p=[0.5, 0.5, 0, 0, 0])
'blue'
We can also use np.random.choice to take a sample with more than 1 element (sample size > 1) by using the size argument.
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles, size=4)
array(['blue', 'green', 'yellow', 'green'], dtype='<U6')
Here we see that some colors were chosen more than once. The np.random.choice function assumes that samples are being takes with replacement which means that every time I choose a marble, I put it back in the hat before choosing the next marble. Many times, we want to sample without replacement, like in the context of sampling participants for a survey experiment. The same person cannot participate in your experiment twice. To sample without replacement, set the replace argument to False. Note that when sampling without replacement, the size used cannot exceed the number of elements in your list.
marbles = ["red", "blue", "yellow", "green", "brown"]
np.random.choice(marbles, size=4, replace=False)
array(['green', 'red', 'brown', 'yellow'], dtype='<U6')
SRS’s are very useful in practice as they allow a researcher to mathematically or computationally quantify variation due to sampling (i.e. the precision of a statistic). The downside of a SRS is that it requires a sampling frame - a list of names or IDs of all units in a population. In our marble example, the sampling frame was our marbles array and had a size of 5. Acquiring such a sampling frame is impractical for large populations. Now that we have experimented with simple random sampling, we will introduce a few more sampling designs that make use of simple random samples.
Stratified Random Sampling#
Stratified random sampling divides the population into sub-populations of similar units (called strata) and chooses a separate SRS for each stratum. The figure below depicts a stratified random sample of 10 units from a population of 100 with 5 strata.

Stratified samples allow a researcher to gain more exact information than SRS’s of the same size, by ensuring that each stratum is equally represented in the sample. Many universities employ stratified random sampling when conducting surveys gauging student or faculty opinions. Those conducting the survey split the population of university students into strata by year (e.g. first years, second years, third years, and fourth years); then, they take a simple random sample of students from each stratum. This sampling design works well when cases within a stratum are similar but there are large differences between strata. However, it has the same downside as a SRS as it too needs sampling frames for each stratum.
Cluster Sampling#
Cluster sampling also splits the population into sub-populations, while stratified sampling takes a random sample within those groups, cluster sampling takes a random sample of those groups, or clusters. The figure below shows a cluster sample of 10 units from a population of size 100 with 20 clusters.
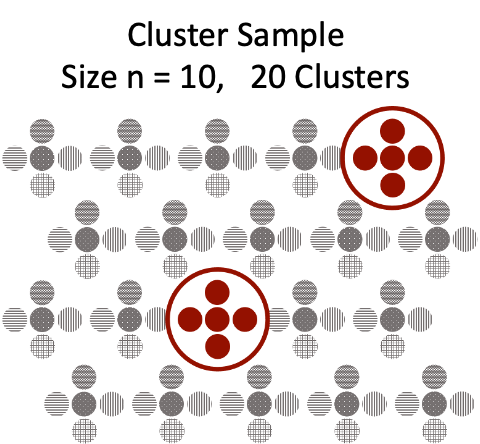
Clusters are chosen so that each cluster is similar to the full population. Ideally, there should be small variation between clusters (all clusters should look similar) but large variation within clusters (each cluster consist of a diverse sample). This type of sample is commonly used for geographical and market research. For example, the head of a major department store may be interested in how well a particular product is selling. Rather than analyzing all sales for all stores across the whole country, the market research team would cluster sales by store and take a random sample of stores.
Multistage Sampling#
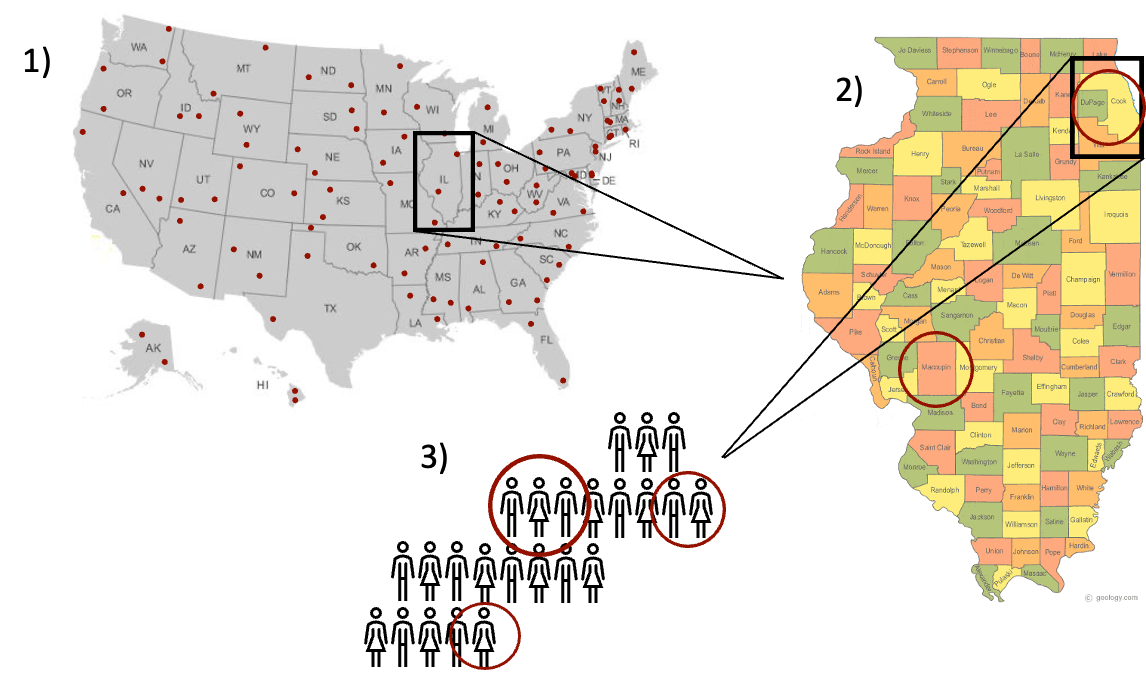
The next type of sampling we will discuss, multistage sampling, conducts sampling in stages and is often used for large nationwide samples of households or individuals. The major advantage of multistage sampling is that it does not require a complete sampling frame. For example, consider a polling company interested in obtaining a generalizable sample of American households. First, they might stratify households by state to ensure sampling from each state. Within states, they might cluster households by county and take a simple random sample of those counties. Lastly, they take a simple random sample of n households from each of the sampled counties. This sampling strategy is depicted below. Multistage sampling mixes stratified and cluster sampling in stages and, as a result, the researcher never requires a list of all households in the US, but rather a sampling frame of US counties and then a sampling frame of households within a much smaller subset of US counties.
Biased Sampling#
There are two sampling designs that suffer from a lack of generalizability yet sometimes cannot be avoided. The first is known as a convenience sample. A convenience sample is, as its name suggests, a sample that is collected out of ease of access for the researchers. Looking through research in psychology in particular, many researchers collect a convenience sample of students from introductory psychology courses. Though this is an easy way of gathering a sample, it is not the most generalizable, as introductory psychology students are likely not representative of the broader population the researchers seek to understand.
A second example of a sampling design that is not generalizable is the voluntary response sample, where participants volunteer to be part of the study. Restaurant reviews provide a nice example of a voluntary response sample. Those with strong opinions of the restaurant (either positive or negative) are more likely to write reviews. Voluntary response samples oversample those who feel strongly about the topic being studied and undersample those who do not care as much. These samples are always biased, or not representative of the broader population.